Проект открытого кода научных исследований ФКН (Михаил Гущин, OSEDUCONF-2024)
Материал из 0x1.tv
- Докладчик
- Михаил Гущин


На факультете компьютерных наук НИУ ВШЭ стартовал проект по открытому коду, где сотрудники и студенты могут разместить код своих проектов.
Расскажем, почему возникла необходимость в таком проекте, и какие цели стоят перед ним. Обсуждаем какую пользу, которую проект несёт для факультета и партнёров.
Также рассматриваем несколько примеров открытых библиотек, разработанных сотрудниками факультета.
Содержание
Видео
Презентация












Thesis
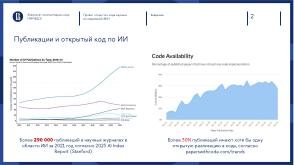
Согласно отчёту о состоянии искусственного интеллекта (ИИ) от Университета Стэнфорда [1] в 2021 году были опубликованы более 290 000 статей в научных журналах в области ИИ. При этом только около 30% публикаций имеют хотя бы одну открытую реализацию в коде, согласно статистике сайта статей с открытым кодом[2]].
Открытый код научных исследований необходим для повышения качества и прозрачности научных работ, а также для стимулирования инноваций и сотрудничества между учёными. Он позволяет исследователям и другим специалистам изучать и анализировать научные работы, выявлять ошибки и недостатки в них, что способствует повышению доверия к результатам исследований. Также открытый код облегчает сотрудничество между учёными, позволяя им совместно работать над решением научных проблем и обмениваться знаниями. Он даёт возможность повторно использовать существующие работы, экономя время и ресурсы. Использование программного обеспечения с открытым исходным кодом снижает затраты на исследования, так как не нужно покупать дорогостоящие проприетарные программы. В целом, открытый код научных исследований способствует развитию науки, повышению качества исследований и укреплению международного научного сообщества.
В 2021 году уже существовало более 330 000 проектов с открытым кодом в области ИИ[3].
К 2022 году эти проекты собрали на Github в сумме более 8 000 000 звёзд. Самыми популярными из них
являются библиотеки широкого назначения такие как Tensorflow, OpenCV, Keras,
PyTorch, Scikit-learn и другие.

Открытый код способствует повышению популярности результатов научных исследований. В таблице приведены данные о количестве цитирований на Google Scholar, а также число звёзд у репозиториев на Github для некоторых статей конференции NeurIPS в 2021—2023 годах.

итирования отражают интерес к результатам исследований со стороны
научного сообщества. Тогда как число звёзд выражает интерес и со стороны исследователей, и со стороны разработчиков и
инженеров в области ИИ. Результаты[4] показывают, что число звёзд обычно существенно превышает количество цитирований
соответствующих статей.
Наличие открытого кода способствует росту числа цитирований, поскольку облегчает другим исследователям воспроизведение и использование результатов в своих работах. График показывает, что публикация кода вместе со статьёй дополнительно повышает видимость результатов и приводит к росту популярности.
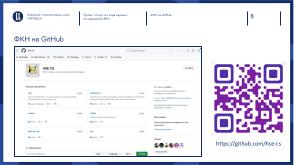
Факультет компьютерных наук (ФКН) НИУ ВШЭ каждый год выпускает десятки научных статей в высокорейтинговых журналах и выступает на конференциях с рейтингом Core A[3]. С целью увеличить видимость результатов исследований среди сотрудников факультета, студентов, а также партнёров и внешних разработчиков был запущен проект открытого кода ФКН. Создана страница на Github[5], где сотрудники и студенты факультета могут разместить код своих проектов и получить обратную связь от коллег и сообщества.
Одинм из примеров открытого кода ФКН является библиотека LaNeta[6] для оценки времени примешивания между двумя популяциями при двух пульсах миграции. В библиотеке реализован алгоритм, который построен на математической теории неравновесного сцепления трёх генетических локусов при примешивании популяций[7].
Он позволяет точно исследовать недавнюю (в пределах нескольких десятков поколений) историю примешивания популяций в сложных сценариях, для которых существовавшие ранее методы были неприменимы или неточны. Библиотека будет интересна всем, кто занимается популяционной геномикой.
Студентами и сотрудниками факультета была разработана библиотека Fulu[8].
В ней собраны несколько методов для аппроксимации кривых блеска астрономических объектов с использованием машинного обучения. В библиотеке реализованы алгоритмы на основе гауссовских процессов, а также некоторые другие, с использованием нормализующих потоков и байесовских нейронных сетей[9].
Библиотека будет полезна астрономам и прикладным исследователям на стыке машинного обучения и астрофизики, который изучают сверхновые.
Также у нас есть библиотеки общего назначения. Например, библиотека генеративных моделей Probaforms[10]. Она содержит реализации вариационных автокодировщиков, генеративно-состязательных сетей и нормализующих потоков для табличных данных. С их помощью можно решать задачи регрессии и классификации, оценивать неопределённость прогнозов, учить распределения данных, создавать синтетические данные.
Мы призываем студентов и сотрудников факультета участвовать в разработке открытого кода. Проект позволит улучшить прозрачность исследований, будет способствовать сотрудничеству между учёными и студентами, упростит повторное использование наработок и увеличит видимость результатов исследования за пределами университета.
!.jpg)
Примечания и ссылки
- ↑ Maslej N., Fattorini L., Brynjolfsson E., Etchemendy J., Ligett K., Lyons T., et al. (2023). Artificial intelligence index report 2023. [1]
- ↑ [paperswithcode.com/trends
- ↑ 3,0 3,1 Избранные публикации сотрудников факультета. [2]
- ↑ Данные получены с помощью сервиса [3]
- ↑ Репозитории с открытым кодом ФКН. [4]
- ↑ LaNeta. [5]
- ↑ Liang M., Shishkin M., Mikhailova A., Shchur V., \& Nielsen R. (2022). Estimating the timing of multiple admixture events using 3-locus linkage disequilibrium. PLoS genetics, 18(7), e1010281. [6]
- ↑ Fulu. [7]
- ↑ Demianenko M., Malanchev K., Samorodova E., Sysak M., Shiriaev A., Derkach D., \& Hushchyn M. (2023) Understanding of the properties of neural network approaches for transient light curve approximations. Astronomy \& Astrophysics, 677, A16. [8]
- ↑ Probaforms. [9]